Using the data frame you created by importing the gapminder.tsv data set, determine which country at what point in time had the lowest life expectancy. Conduct a cursory level investigation as to why this was the case and provide a brief explanation in support of your explanation.
A package is a set of various python modules that contain init.py files, they usually are shortcuts to enable other functions.
A library is a collection of packages.
The two steps to import a package is to import a library and then import the package from the library. There is the optional ability of giving a package an alias. For example
import pandas as pd
import math as md
it is a good idea to use an alias because it makes things easier when using the packages multiple times when writing out code.
Describe what is a data frame? Identify a library of functions that is particularly useful for working with data frames. In order to read a file in its remote location within the file system of your operating system, which command would you use? Provide an example of how to read a file and import it into your work session in order to create a new data frame. Also, describe why specifying an argument within a read_() function can be significant. Does data that is saved as a file in a different type of format require a particular argument in order for a data frame to be successfully imported? Also, provide an example that describes a data frame you created. How do you determine how many rows and columns are in a data frame? Is there an alternate terminology for describing rows and columns?
A data frame is the most common way of storing data through computer science and data science. They allow an individual to organize variables through numerous factors both nominal and numerical.
A library of functions that is particularly useful for working with data frames would be pandas.
If I wanted to make a pandas data frame by reading in a file from my computer I would code
vaccine = pd.read_csv('vaccine_data.csv')
This would read in the data from vaccine into pandas and then it would name the data frame vaccine. The read_csv() function is significant because you can be reading in various different types of files. read_csv() is the command used to read in a comma-separated value file. An example of a data frame that is comma-separated is Microsoft excel. Another example of data you could be reading in would be tab separated data or tsv. For that scenario you would want to code something like the following.
pd.read_csv('gapminder.tsv', sep ='\t')
Below is a pandas data frame that represents my practice personal bests for my senior year of track in field for the hammer throw.
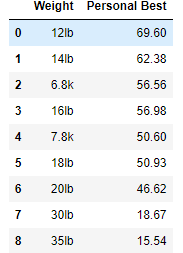
This data frame is very simple as there are only two variables to practice training personal bests. That being the weight of the implement that is being thrown and then the distance of the implement that was thrown. The distance is in meters. Both of these variables are labeled in the columns.
Alternative terminology for rows and columns would be variables and observations. Where variables would be the columns and observations being the rows.
Import the gapminder.tsv data set and create a new data frame. Interrogate and describe the year variable within the data frame you created. Does this variable exhibit regular intervals? If you were to add new outcomes to the raw data in order to update and make it more current, which years would you add to each subset of observations?
Below is the data frame that is given from the gapminder file.
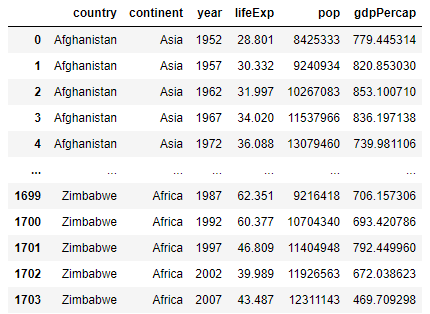
Currently the above data frame is in alphabetical order with Afghanistan being the first country while Zimbabwe is the last. The maximum year is 2007 which I discovered with the following code.
Year = df['Year']
Year.max()
To update the data I would find information to import that would allow all the data up to 2020. I’m not sure how this would effected the average life expectancy, medical advancements have increased dramatically the past decade. But also that would factor the deaths from the COVID-19 pandemic. More than likely I would assume the average life expectancy would still increase just because 2008-2019 would out weigh 2020.
Using the data frame you created by importing the gapminder.tsv data set, determine which country at what point in time had the lowest life expectancy. Conduct a cursory level investigation as to why this was the case and provide a brief explanation in support of your explanation.
When the data was then ordered by life expectancy the country with the lowest life expectancy was shown to be Rwanda in 1992. The average life expectancy for Rwanda at that time was 23.599 which was 5 years over the next country being Afghanistan in 1952 with an average life expectancy of 28.801. This was because of mass genocide in Rwanda during a civil war.
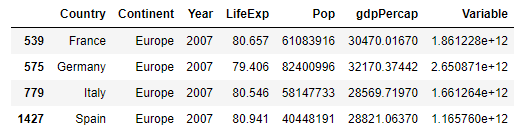
Using the data frame you created by importing the gapminder.tsv data set, multiply the variable pop by the variable gdpPercap and assign the results to a newly created variable. Then subset and order from highest to lowest the results for Germany, France, Italy and Spain in 2007. Create a table that illustrates your results (you are welcome to either create a table in markdown or plot/save in PyCharm and upload the image). Stretch goal: which of the four European countries exhibited the most significant increase in total gross domestic product during the previous 5-year period (to 2007)?
Below is a data frame that is a subset with 4 countries being Italy, France, Germany and Spain
You have been introduced to four logical operators thus far: &, ==, | and ^. Describe each one including its purpose and function. Provide an example of how each might be used in the context of programming.
| In class so far we have been introduced to four logical operators which are &, | , == and ^. |
& allows you to subset with two criteria. If you wanted to subset a data frame in Afghanistan under a particular year & is the proper logical operator.
df[(df.Country == 'Afghanistan') & (df.Year == 2007)]
The == logical operator allows for you to set the columns to the variables that you wish to use.
| If you wanted to set numerous variables in one column you would use the | logical operator which is the OR function. |
sub = df[(df.Country == 'Germany') | (df.Country == 'France') | (df.Country == 'Spain') | (df.Country == 'Italy')]
The ^ logical operator will call a row if it meets either variable but not both. If you used ^ between France and 2009, that will call all rows that have France or 2009 but not France and 2009.
Describe the difference between .loc and .iloc. Provide an example of how to extract a series of consecutive observations from a data frame.
Two things we learned in class were how to use loc and iloc. Iloc is used to call a row by its integer position, starting with 0 while loc can fetch rows by their title. There is also an additional argument that is offered after selecting the rows which allows the user to select the columns.
df.iloc[0:4]
The above code would call the rows between row 0 and row 5
df.loc[1]
The above code will call the second row in the column.
Describe the difference between .loc and .iloc. Provide an example of how to extract a series of consecutive observations from a data frame.
API stands for Application programing interface . It is another computer that allows you to access data from a website and then import it into a data frame through python.
To properly do this you need to import the following
import os
import requests
import pandas as pd
Then you need to call the URL
url = 'http://api.covidtracking.com/v1/states/daily.csv'
after that you need to code the following
data_folder = 'data'
if not os.path.exists(data_folder):
os.makedirs(data_folder)
file_name_short = 'ctp_' + str(dt.now(tz=pytz.utc)).replace(' ', '_').replace(':', '_') + '.csv'
file_name = os.path.join(data_folder, file_name_short)
r = requests.get(url)
with open(file_name, 'wb') as f:
f.write(r.content)
import pandas as pd
df = pd.read_csv(file_name)
Describe the apply() function from the pandas library. What is its purpose? Using apply) to various class objects is an alternative (potentially preferable approach) to writing what other type of command? Why do you think apply() could be a preferred approach?
One of the most useful tools we use in class is the apply() function which comes from the Pandas library. It is one of the most useful tools because it allows you to input things like lambdas to the entire data frame. Basically apply() is the most efficient way to work on the entire data frame. Other ways to do that is a loop but apply() is faster and more efficient.
Also describe an alternative approach to filtering the number of columns in a data frame. Instead of using .iloc, what other approach might be used to select, filter and assign a subset number of variables to a new data frame?
Another way to filter columns and rows in data frames other than using .iloc is to just call the columns and create a copy of the data frame that you want.
you can that by coding something like the following
subset = ['Pop', 'Country', Continent]
filter = df[subset].copy()